- Published on
AmberVision
- Authors
- Name
- Suraj Shah
- @surajs98
As part of GW’s computer science program, every senior is required to work with a team on a capstone project. Now some of these projects are given and can be tweaked, or can be a collaboration with a professor in the computer science department for a project they are working on.
My team and I opted for the latter and worked with Dr. Robert Pless to develop AmberVision.
Background
AmberVision is one part of a solution to the question: how can we leverage existing technology to search for Amber Alert victims? AmberVision has a simple goal -- detect cars and display these detections to law enforcement. With this goal in mind, we aimed to use a clear and concise design method so that law enforcement can successfully receive the information we provide. This problem is extremely important because Amber Alerts were created many years ago, but the lack of technology involved in helping these victims is glaringly evident through our year-long project.
We took a deep dive into the statistics of Amber Alerts including the annual number of victims, but also positive stats such as the rescue rate and the information related to an Amber Alert.
What we focused on was the metadata for cars used in these abductions. We noticed a pattern for these Amber Alerts — a vehicle make/model (Toyota), size (sedan), and color (red). We realized that we weren’t trying to solve a car classifier because we were collecting data from low-resolution traffic cameras throughout the DC area. So we decided to focus our efforts on detecting cars based on their size and color.
Tech
What we opted for was a real-time object detection tool that allows law enforcement to view a web app and see the detected vehicles on the streets of DC.
Data collection
We first needed to figure out how we were gonna collect this data. Initially, we started reaching out to the District Department of Transportation (DDOT), but what we found was rather interesting — DC doesn’t actually own its cameras. Instead, a third-party source actually owns traffic cameras and licenses it out to local governments. Through further investigation, we found a company with a majority stake of traffic cameras in DC, know as TrafficLand. We reached out to them, explaining that we were college students looking for a way to access their API for free, and they agreed for the period from September 2019 to May 2020.
Object detection
Great, so we have the data! Now what? Well, we needed to actually use the data somehow to solve our problem. The first thing we noticed was that the resolution was terrible. These low-res cameras looked like they came from the ’90s, which to be honest, they probably did. We needed an object detection algorithm that worked on anything and I mean literally ANY objects.
But first -- what is object detection? To briefly explain, object detection uses computer vision to find certain objects in images/videos. It’s exactly what it sounds like, it detects objects using complicated math and computer vision algorithms.
While figuring out what tools and technologies were out there, we had heard of You Only Look Once (YOLO), which only looks at an image one time and gets detections. This was the ideal speed and accuracy we were looking for, so we decided to implement that on our traffic cameras.
Color detection
We also focused on getting the colors of these cars, but this was really hard — much harder than we thought. We decided to use PCA embedding which doesn’t mean a lot without an explanation. Essentially, PCA stands for Principal component analysis, which means it runs an algorithm to get a best-fitting line in any dimension. It’s similar to linear regression, but on a larger scale. Using this technique, we could convert pixels into a 2D plot of each pixel in an image, and classify the RGB values to find the correlated colors.
This proved to be very difficult because the images were so grainy and low-res, that most pictures ended up with very low accuracy scores or colors that were simply not right. This was definitely a learning experience and one that should be noted for anyone who tries to use PCA embeddings in object detection.
Results
Let’s show what we actually developed and our results!
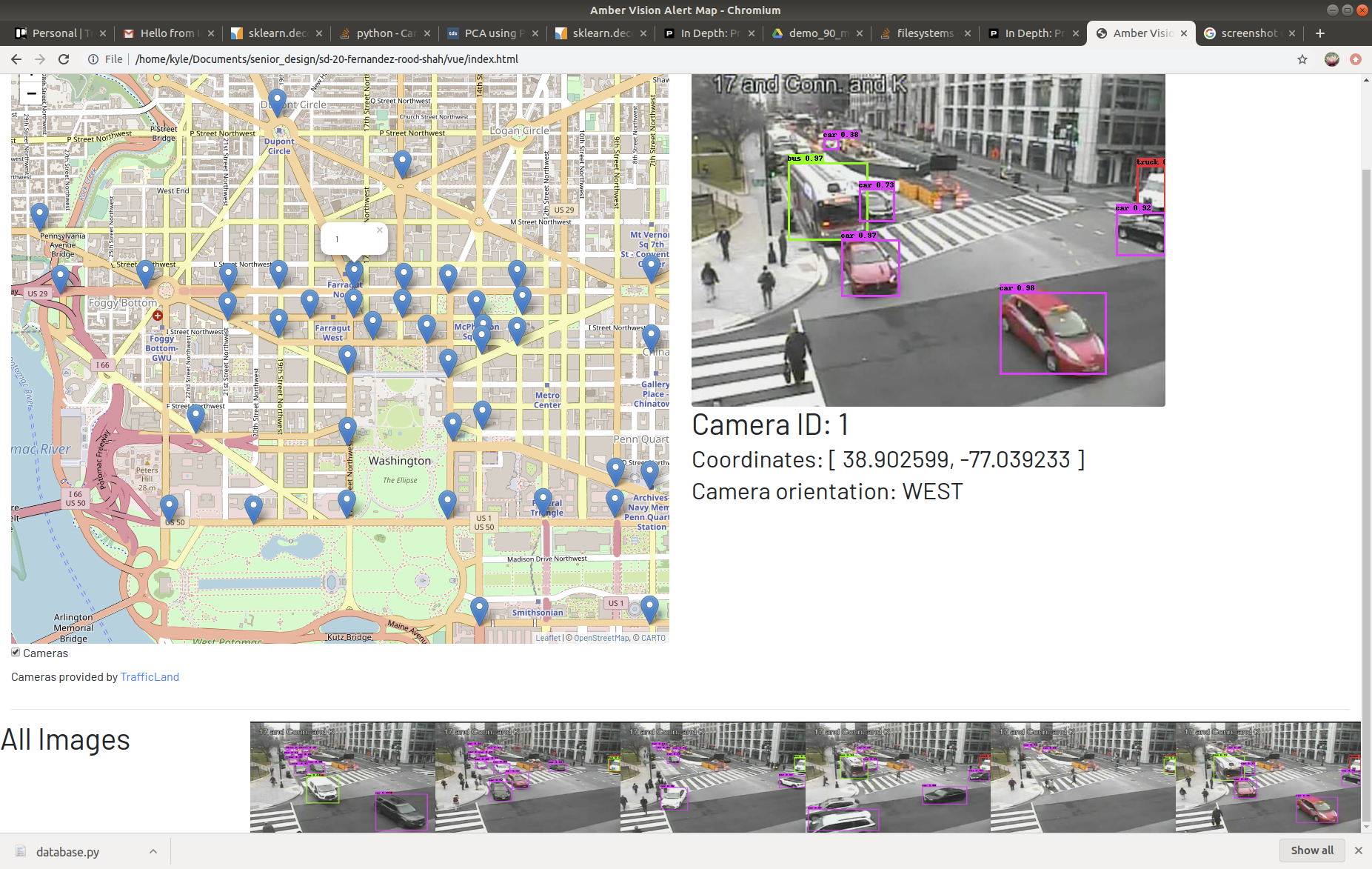
The image below shows detected cars, buses, and trucks in one frame with a different color based on each size. This was one of our best images that showed the power of YOLO and its ability to detect vehicles in such low-resolution cameras.



Let’s show what we made to present our web application. We created this project in Vue.js as one of the team members was previously experienced in this front-end framework. As you can see, it shows a map of the location of the cameras in DC and the latest image with the vehicles detected. Super cool!

Technologies used
Here, I’ll mention the tools and technologies we used. We used Python for the backend and Vue.js for the front-end web app.
Here’s a list of most of the technologies we used:
Python Flask, MongoDB, Sklearn, cv2, Matplotlib, Pandas, Scipy
Vue.js: Leaflet. Axios, Bootstrap-Vue, Vanilla JS, HTML
Why this is important
My team and I worked on a project that will, yes, receive a grade, but the implications are much larger than that. We demonstrated the powerful effect of using our minds for something bigger than school — the importance of doing social good. What got me through this project was the ability to realize that although we were unable to fully develop this project into a full-scale application, someone else can, with the ideas we started.
We have a real ability to help victims of abduction and save those using the tools and technology already out there. This was the first time in my life I realized I might not need to donate a million dollars to help others, but I can use my skills to help solve real problems out there.
Sources
Unfortunately, the web application was never hosted online due to COVID-19 implications and the code is private on GitHub due to class restrictions. I do have the latest code and if there’s enough of an interest to reopen this project, I’d love to share the code with those interested. Feel free to contact me. However, you can see our work on our GitHub pages for the project here.